
Integrate Scrapy with ProxyPanel
2023-06-08 14:26

2023-06-08 14:26

Scrapy is a comprehensive web scraping and crawling framework. It not only sends HTTP requests but also parses HTML documents and performs other tasks, combining functionalities of libraries like Requests and BeautifulSoup. Scrapy is highly extensible, allowing custom functionality additions. Beyond building web scrapers or crawlers, Scrapy simplifies deployment to the cloud, making it a versatile tool for data extraction and web automation projects.
we will scrape a simple quotes website using Scrapy and ProxyPanel proxies. We'll extract quotes from the website and save them into a JSON file.
Prerequisites
Install Scrapy using pip:
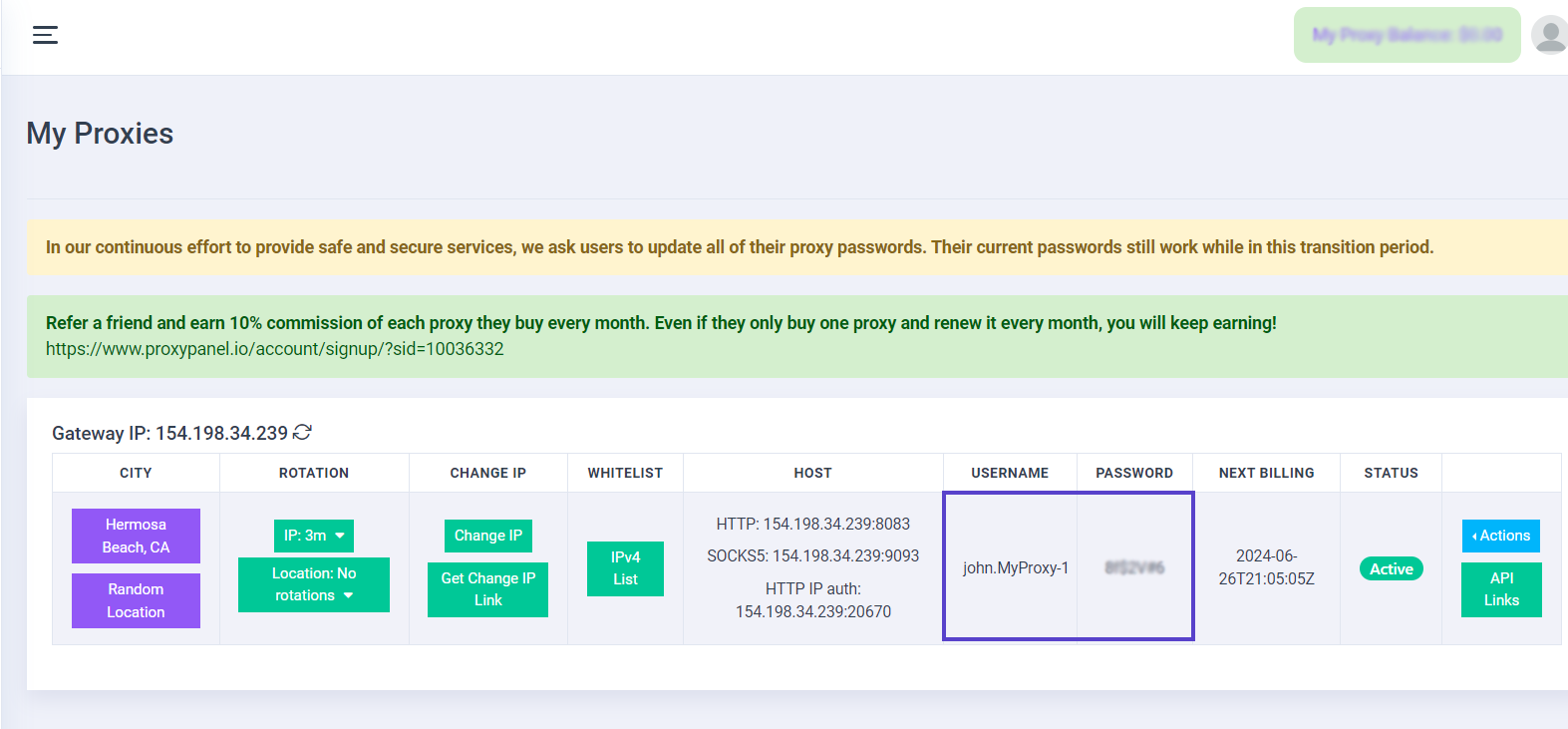
Go to your Dashboard panel and navigate to the "My Proxy" section to view your IP information.
Click on the "Show Password" button and enter your account password to display your proxy password.
Open scrapy.py and add the following code. Replace username, password, your_proxy, and port with the actual details provided by your proxy service:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/tag/humor/",
]
# Define your proxy URL with username and password
proxy = "http://username:password@your_proxy:port"
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, callback=self.parse, meta={'proxy': self.proxy})
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"author": quote.xpath("span/small/text()").get(),
"text": quote.css("span.text::text").get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse, meta={'proxy': self.proxy})
Run your script using this command:
scrapy runspider scrapy.py -o quotes.json